目录:
1.25条越早知道越好的建议
2.越早知道越好的道理
3.越早越好是什么意思
4.一些越早知道会越好的人生经验
5.越早越好怎么说更有趣
6.越早知道越好的经验
7.40个越早知道越好的道理
8.越早越好的意思
1.25条越早知道越好的建议
这些策略是SEO优化的基本原则,通过结合它们,您可以提高您的网站在搜索引擎中的排名,从而吸引更多的有针对性流量并提升在线可见性。请记住,SEO是一个长期的过程,需要持之以恒的努力和监控。
2.越早知道越好的道理
[Math] 常见的几种最优化方法www.cnblogs.com/maybe2030/p/4751804.html
3.越早越好是什么意思
百度上基本是抄的这一篇的谷歌站群软件,总结的很好,不过有一些遗漏,后面补上总的来说,神经网络的最优化方法独立一大块的内容,非常多这块放到深度学习的专栏里整理好了免得太乱了,这里主要总结一下传统机器学习算法中常用到的各种最优化方法。
4.一些越早知道会越好的人生经验
1. 梯度下降法(Gradient Descent) 梯度下降法是最早最简单,也是最为常用的最优化方法梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局最优解一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。
5.越早越好怎么说更有趣
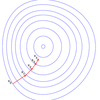
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最谷歌站群软件速下降法“最速下降法越接近目标值,步长越小,前进越慢梯度下降法的搜索迭代示意图如下图所示:

6.越早知道越好的经验
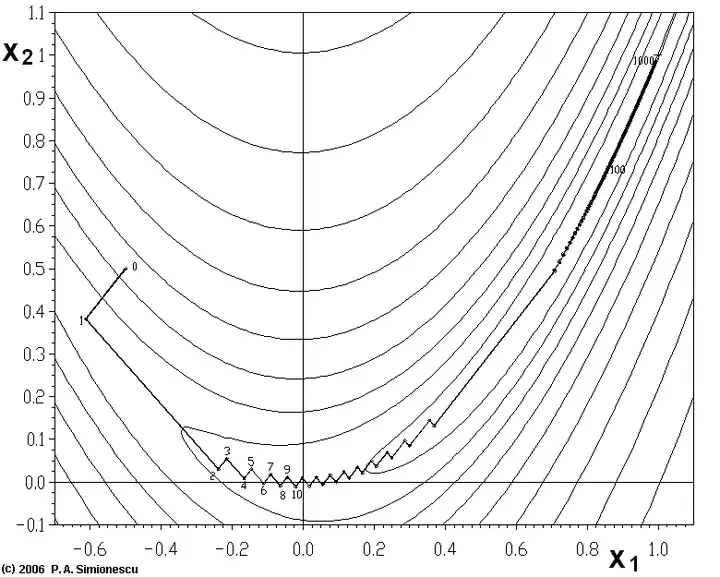
梯度下降法的缺点: (1)靠近极小值时收敛速度减慢,如下图所示(这是因为越靠近极小值,参数的权重更新量越小,自己实现一个线性回归就知道了); (2)直线搜索时可能会产生一些问题(比较容易在极小值点附近震荡);
7.40个越早知道越好的道理
(3)可能会“之字形”地下降。(特征没做归一化,不同量纲导致的梯度更新量差别大,迭代过程中容易偏来偏去的)
8.越早越好的意思
从上图可以看出,梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代 在机器学习中,基于基本的谷歌站群软件梯度下降法发展了3种梯度下降方法,分别为SGD,MINI-BATCH和whole batch。
比如对一个线性回归(Linear Logistics)模型,假设下面的h(x)是要拟合的函数,J(theta)为损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。
其中m是训练集的样本个数,n是特征的个数
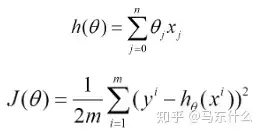
1)批量梯度下降法(Batch Gradient Descent,BGD) (1)将J(theta)对theta求偏导,得到每个theta对应的的梯度:
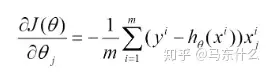
(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta:
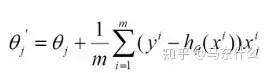
(谷歌站群软件3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度会相当的慢所以,这就引入了另外一种方法——随机梯度下降 对于批量梯度下降法,样本个数m,x为n维向量,一次迭代需要把m个样本全部带入计算。
2)随机梯度下降(Stochastic Gradient Descent,SGD) (1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:
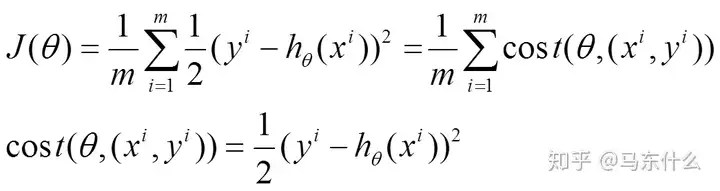
(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta:
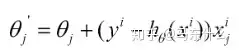
(3)随机梯度下降是通过每个样本来迭代谷歌站群软件更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。
但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向(确切一些说 sgd更容易带来极值附近的震荡) 随机梯度下降每次迭代只使用一个样本,迭代一次计算量为n2,当样本个数m很大的时候,随机梯度下降迭代一次的速度要远高于批量梯度下降方法。
两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次谷歌站群软件数为代价,换取了总体的优化效率的提升增加的迭代次数远远小于样本的数量对批量梯度下降法和随机梯度下降法的总结:批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近(小样本可能导致不精确,大样本差别不是很大),适用于大规模训练样本情况。
为了方便描述,用keras写线性回归然后观察参数变化来直观理解importosfromkeras.modelsim谷歌站群软件portSequentialfromkeras.layersimportDenseimport。
randomimportnumpyasnpfromsklearn.preprocessingimportStandardScalerimportpandasaspdimportmatplotlib.pyplot
aspltfromkerasimportoptimizerssgd=optimizers.SGD(lr=0.01)defseed_everything(seed=0):random.seed(seed)
os.environ[PYTHONHASHSEED]=str(seed)np.random.谷歌站群软件seed(seed)SEED=42seed_everything(SEED)fromsklearn.datasets
importmake_classificationX,y=make_classification(n_samples=10000,# 样本个数n_features=25,# 特征个数n_informative
=10,# 有效特征个数n_redundant=5,# 冗余特征个数(有效特征的随机组合)n_repeated=5,# 重复特征个数(有效特征和冗余特征的随机组合)n_classes=2,# 样本类别random_state
=0)X=StandardScaler().fit_谷歌站群软件transform(X)#X=np.c_[X,np.ones(10000).flatten()]# keras 本身自带偏置不需要额外添加model=
2.3.2 视频内容: 制作教育性和娱乐性的视频内容,以在YouTube等视频平台上分享。
Sequential()model.add(Dense(units=1,input_dim=25))model.compile(optimizer=sgd,loss=mse)#注意,这里的sgb不是通常意义的随机梯度下降
#而是梯度下降法的统称,如果每一个batch一个样本就是随机梯度下降,否则就是mini-batch,如果一个#batch是全部数据就是bgd谷歌站群软件## 这里就用bgdweights=[]forstepinrange
(500):model.train_on_batch(X,y)weights.append(model.get_weights()[0])weights=pd.DataFrame(np.concatenate
(weights,axis=1).T)plt.plot(weights)
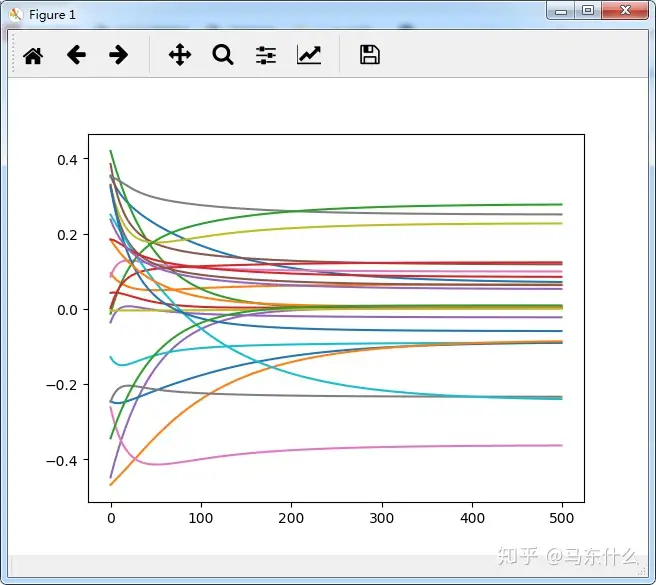
(BGD)梯度下降法的收敛速度2. 牛顿法和拟牛顿法(Newtons method & Quasi-Newton Methods)1)牛顿法(Newtons method) 牛顿法是一种在实数域和复数域上近似求解方程的方法。
方法使用函数f (x)的泰谷歌站群软件勒级数的前面几项来寻找方程f (x) = 0的根牛顿法最大的特点就在于它的收敛速度很快(因为用到了二阶导)马东什么:梯度下降法和一阶泰勒展开的关系129 赞同 · 19 评论文章

我们前面推导了梯度下降法和一阶泰勒展开的关系,实际上牛顿法也可以用二阶泰勒展开推导得到,只不过因为存在二次项所以求解方法要比梯度下降法复杂一些,见:
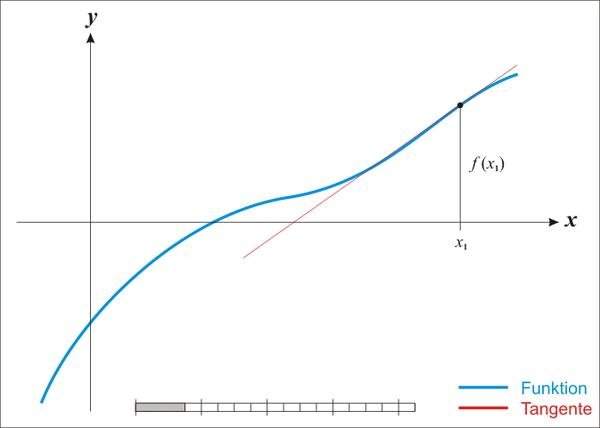
关于牛顿法和梯度下降法的效率对比: 从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,谷歌站群软件还会考虑你走了一步之后,坡度是否会变得更大。
所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想牛顿法的优缺点总结:优点:二阶收敛,收敛速度快;缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
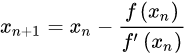
牛顿法的概念公式2)拟牛顿法(Quasi-Newton Methods) 拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。
Davidon设计的这种算法在当时看来是非线性优化领谷歌站群软件域最具创造性的发明之一不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。
通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性这类方法大大优于最速下降法,尤其对于困难的问题另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效如今,优化软件中包含了大量的拟牛顿算法用来解决无约谷歌站群软件束,约束,和大规模的优化问题。
具体步骤: 拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型:
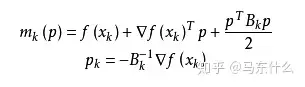
这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点:
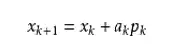
其中我们要求步长ak 满足Wolfe条件这样的迭代与牛顿法类似,区别就在于用近似的Hesse矩阵Bk 代替真实的Hesse矩阵所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk的更新现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:。
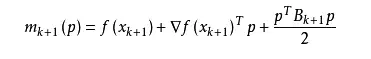
我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求
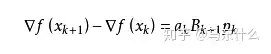
从而得到
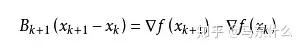
这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。3.极大似然估计、最大后验估计谷歌站群软件的区别马东什么:极大似然估计、最大后验估计127 赞同 · 11 评论文章

10.牛顿法能用于非凸函数吗?from 为什么hessian矩阵非正定时牛顿法会失效、不收敛?使用Newton method进行优化时, 本质上是在目标函数的某点 x0x_{0} 处, 使用其二阶泰勒展开对目标函数进行近似, 既:
(1)f(x)≈f(x0)+∇f(x0)T(x−x0)+12(x−x0)TH(x−x0)f(x) \approx f(x_{0}) \ + \nabla f(x_{0})^{T}(x - x_{0}) \ + \frac{1}{2} (x - x_{0})^{T}H(x - x_{0}) \ta谷歌站群软件g 1
此时 f(x)f(x) 在 x0x_{0} 附近是一个最高次为二次的函数, 我们可以得到其梯度为:(2)∇f(x)=∇f(x0)+H(x−x0)\nabla f(x) = \nabla f(x_{0}) \ + \ H(x - x_{0}) \tag 2
令 ∇f(x)=0\nabla f(x) = 0 , 我们可求得在 x0x_{0}附近的驻点为:(3)x=−H−1∇f(x0)+x0x = -H^{-1} \nabla f(x_{0}) \ + \ x_{0} \tag 3
如果二阶泰勒展开对目标函数足够近似, 且 HH 为正定矩阵, 则函数 f(x)f(x) 在点 x0x_{0} 为凹函谷歌站群软件数, 由(3)必定能走到一个 x0x_{0} 附近的极小值点, 如此得到新的点 x0x_{0}
并重复直到收敛; 但若 HH 非正定, 则分情况讨论. 若 HH 为负定矩阵, 则函数 f(x)f(x) 在点 x0x_{0} 为凸函数, 则(3)得到的是 x0x_{0} 附近的极大值点, 使得目标函数值不减反增; 若
HH 不定, 则其逆矩阵有可能不存在, 此时(3)无法给出有效的信息.综上, Hessian矩阵非正定时, 牛顿法会失效.
ABC数字营销公司:ABC数字营销公司是一家专注于提供卓越的数字营销解决方案的企业。我们拥有一支经验丰富的团队,擅长SEO、社交媒体营销和内容策略。我们的目标是帮助谷歌站群软件客户在竞争激烈的在线市场中脱颖而出。与我们合作,您将获得量身定制的数字营销策略,以实现更多的流量、更高的转化率和可持续的增长。

